
Textual Equilibrium Propagation for Deep Compound AI Systems
A local learning principle for optimizing deep compound AI systems that mitigates exploding and vanishing textual gradients in long-horizon workflows.
Research publications.
Written by Minghui Chen
A local learning principle for optimizing deep compound AI systems that mitigates exploding and vanishing textual gradients in long-horizon workflows.

We systematically explore the potential and challenges of incorporating textual gradient into Federated Learning, introducing FedTextGrad - a novel FL paradigm for optimizing LLMs.

A comprehensive study of delta-parameter pruning that introduces DARq and AdamR to address the limitations of existing methods, enabling efficient storage and deployment of multiple fine-tuned models.

An innovative model interpolation-based local training technique that enhances local training across different clients through regularized model interpolation, acting as a catalyst for seamless adaptation of pre-trained models in federated learning.
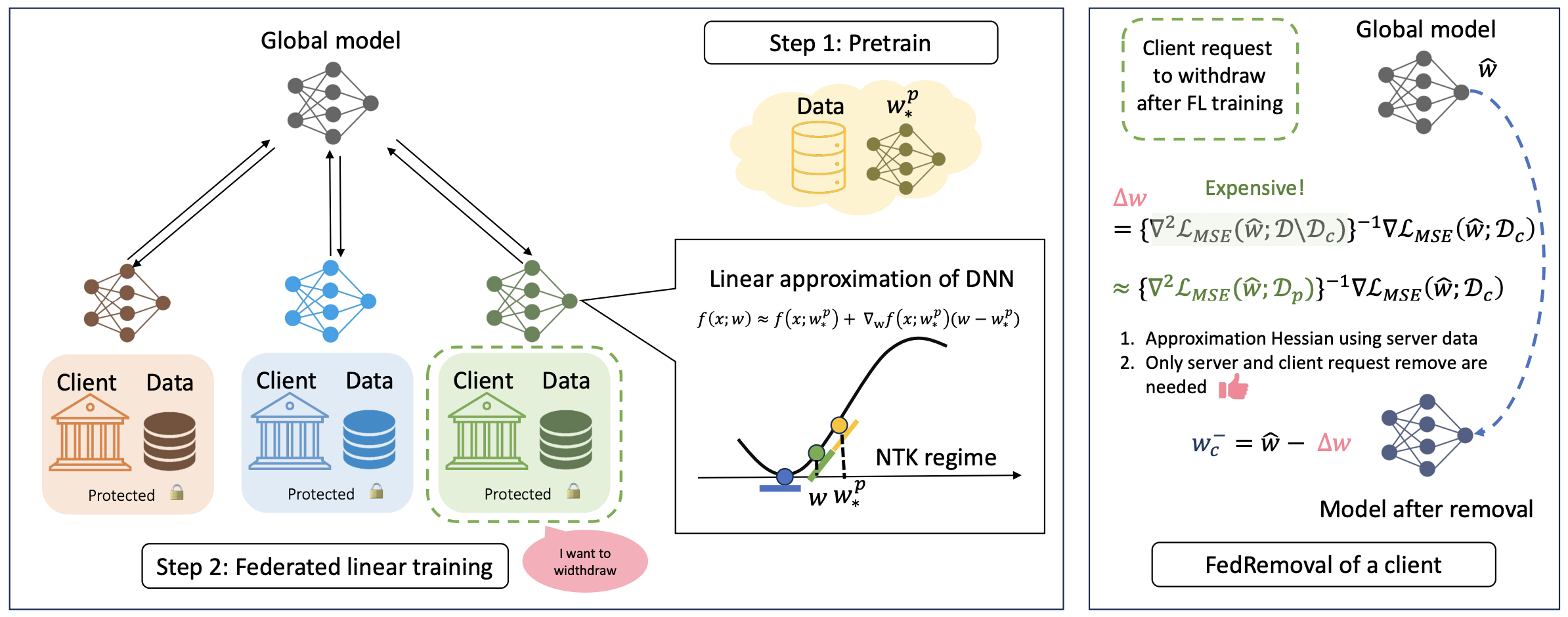
A federated learning framework that enables certified data removal through linear approximation and efficient removal strategies, providing theoretical guarantees for the right to be forgotten.